
If you are wondering why you should take a machine learning test, the answer is simple: skills matter. By taking the test, you will:
- know where you stand in the community of AI practitioners
- review your performance to learn about your strengths and weaknesses
- access personalized study plan to prepare for interviews
- fast track to job opportunities within our network
- get a certificate
And, it’s free. Your results are only ever shared with your permission to refer you to a company. Let’s go over the machine learning test.
I What is the machine learning test
The machine learning test is one of six standardized tests that were developed by a team of AI and assessment experts at Workera to evaluate the skills of people working as a Machine Learning Engineer (MLE), Data Scientist (DS), Machine Learning Researcher (MLR) or Software Engineer-Machine Learning (SE-ML). It is comprised of multiple choice questions selected from a large database, so that different test takers get different questions, and takes 17 minutes to complete.
You can learn more about these roles in our AI Career Pathways report and about the other tests in The Skills Boost.
II What to expect in the machine learning test
Before taking a test, it is important to understand what it evaluates and how it is graded. The grading rubric for the machine learning test includes three categories:
- Understanding ML models, which covers classic machine learning algorithms such as PCA, K-means, K-NNs, SVM, logistic regression, linear regression, and decision trees.
- Understanding methods to train ML models, which encompasses tactics to initialize, optimize, regularize, and select machine learning models.
- Structuring ML projects, which spans strategic decisions to advance machine learning projects such as carrying out error analysis, collecting and labeling good data, splitting and augmenting data, and choosing an evaluation metric.
You will be evaluated and assigned to a skill level in each category: beginning, developing, or accomplished, depending on your mastery of the skill at hand. Your skill level in machine learning will be determined using a combination of your scores across all three categories.
You can learn about the categories and performance levels in the table below.
| Category | Beginning | Developing | Accomplished |
|---|---|---|---|
| Understanding ML models | Demonstrates limited understanding of classic machine learning algorithms. | Demonstrates ability to choose an appropriate machine learning model to solve a given classification or regression problem. | Demonstrates ability to understand various machine learning algorithms, and identify their use cases and shortcomings. |
| Understanding methods to train ML models | Demonstrates limited understanding of methods used to train machine learning models. | Demonstrates ability to understand techniques used to train machine learning models with some effectiveness. This includes optimization algorithms, initialization, regularization and hyperparameter search methods. | Demonstrates ability to understand and apply various optimization algorithms as well as initialization, regularization and hyperparameter search methods. |
| Structuring ML projects | Demonstrates limited understanding of strategies to structure an end-to-end machine learning project. | Demontrates ability to understand classic ML strategies such as error analysis, data split, data collection and evaluation metric selection with some effectiveness. | Demonstrates ability to structure ML projects, and apply methods such as error analysis, data split, data collection, design a labeling process and select proper evaluation metrics to improve model performance. |
At the end of the test, you’ll see your overall skill category in machine learning.
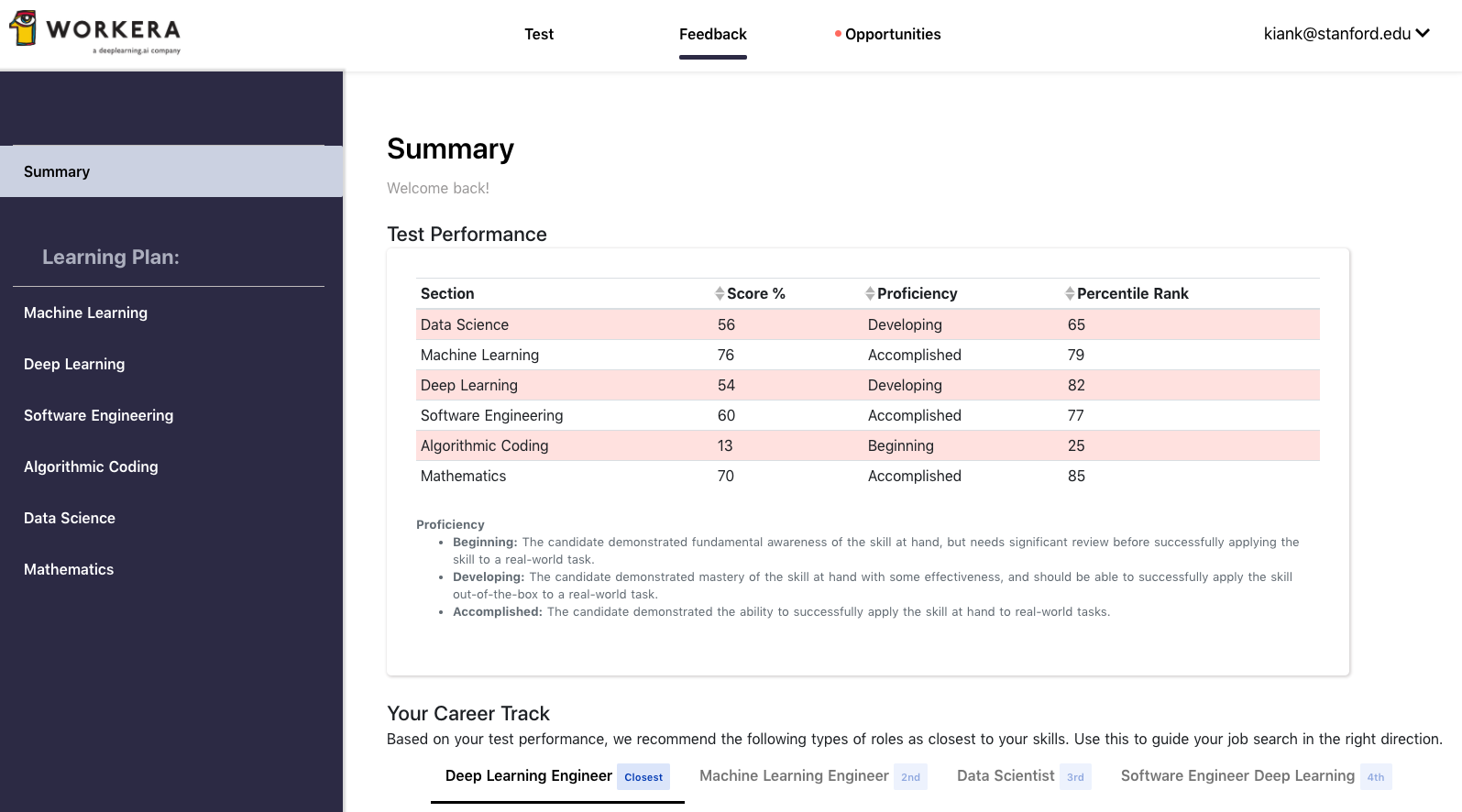
You will also receive feedback for every skills evaluated (e.g., Understanding the impact of K in K-fold cross validation or Understanding the curse of dimensionality in K-nearest neighbors).
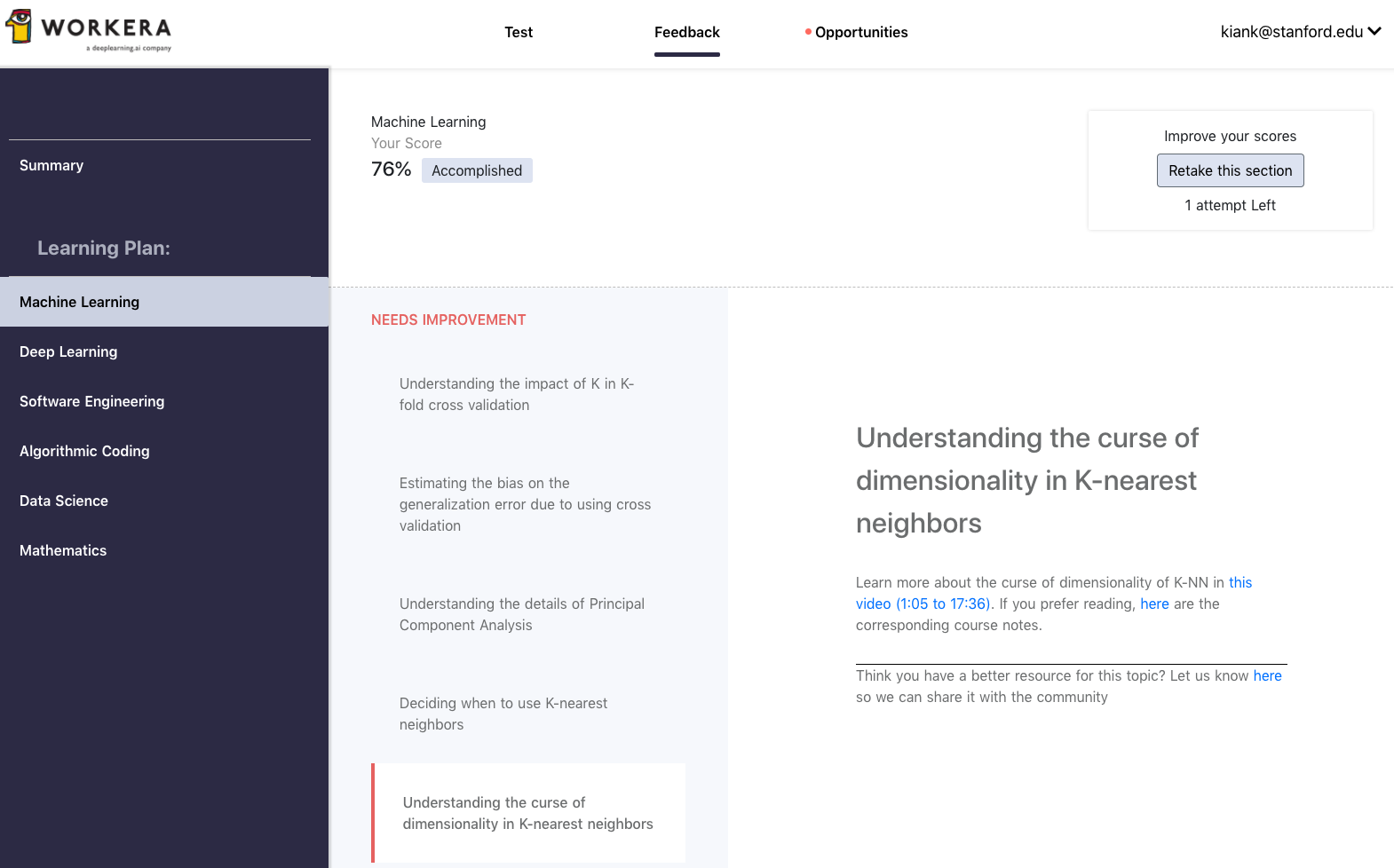
III Machine learning practice questions
Nothing beats practice! Here are examples of questions you might encounter in the machine learning test. Think carefully before selecting your answer. Then, click submit to see the answer and get feedback.
Question 1: supervised vs. unsupervised learning
Question 2: decision tree averages
Question 3: data shuffling
Question 4: correcting mislabeled data
Question 5: choosing a loss function
IV Tips for the machine learning test
Now that you know what to expect in our machine learning test, it’s time to take it! You can take the test up to three times in a 90-day period (unless the test is being administered to you by a company for a job) and your results are only ever shared with your permission. The first test is simply meant to act as a baseline to show you where to start studying. So why wait? Sign up here to take the machine learning test.
Which of the following machine learning algorithms is unsupervised?
random forest
k-nearest neighbors
k-means
support-vector machines
Averaging the output of multiple decision trees helps to$:$
increase bias
increase variance
decrease bias
decrease variance
To optimize your objective function, you are performing full batch gradient descent using the entire training set (not stochastic gradient descent).
Is it required to shuffle your training set?
Yes. If you don't, the optimization will oscillate around the minimum at the end of training.
Yes, in order to help the model generalize to the test dataset.
No, it is not necessary because the dataset can already be considered shuffled from the data collection process.
No, because each update passes through the entire dataset anyway and the order doesn't matter.
You've received 1,000,000 images and have split it in 96%/2%/2% between train, dev and test sets. You've trained your model, and analyzed the results. After working further on the problem, you’ve decided to correct the incorrectly labeled data on the dev set.
Which of these statements do you agree with?
You should also correct the incorrectly labeled data in the test set, so that the dev and test sets still come from the same distribution.
You should correct incorrectly labeled data in the training set as well so as to avoid your training set now being even more different from your dev set.
You should not correct the incorrectly labeled data in the test set, because the test set should reflect the data distribution of the real world.
If you want to correct incorrectly labeled data, you should do it on all three sets (train/dev/test) in order to maintain similar distributions.
You're working on a binary classification task, to classify if an image contains a cat ("1") or doesn't contain a cat ("0").
What loss would you choose to minimize in order to train a model?
$\mathcal{L}= y\log\hat{y}+(1-y)\log(1-\hat{y})$
$\mathcal{L}= -y\log\hat{y}-(1-y)\log(1-\hat{y})$
$\mathcal{L}= \lVert {y - \hat{y}} \rVert^2_{2}$
$\mathcal{L}= \lVert {y - \hat{y}} \rVert^2_{2}$ + constant
Other tests include deep learning, data science, mathematics, algorithmic coding, and software engineering.
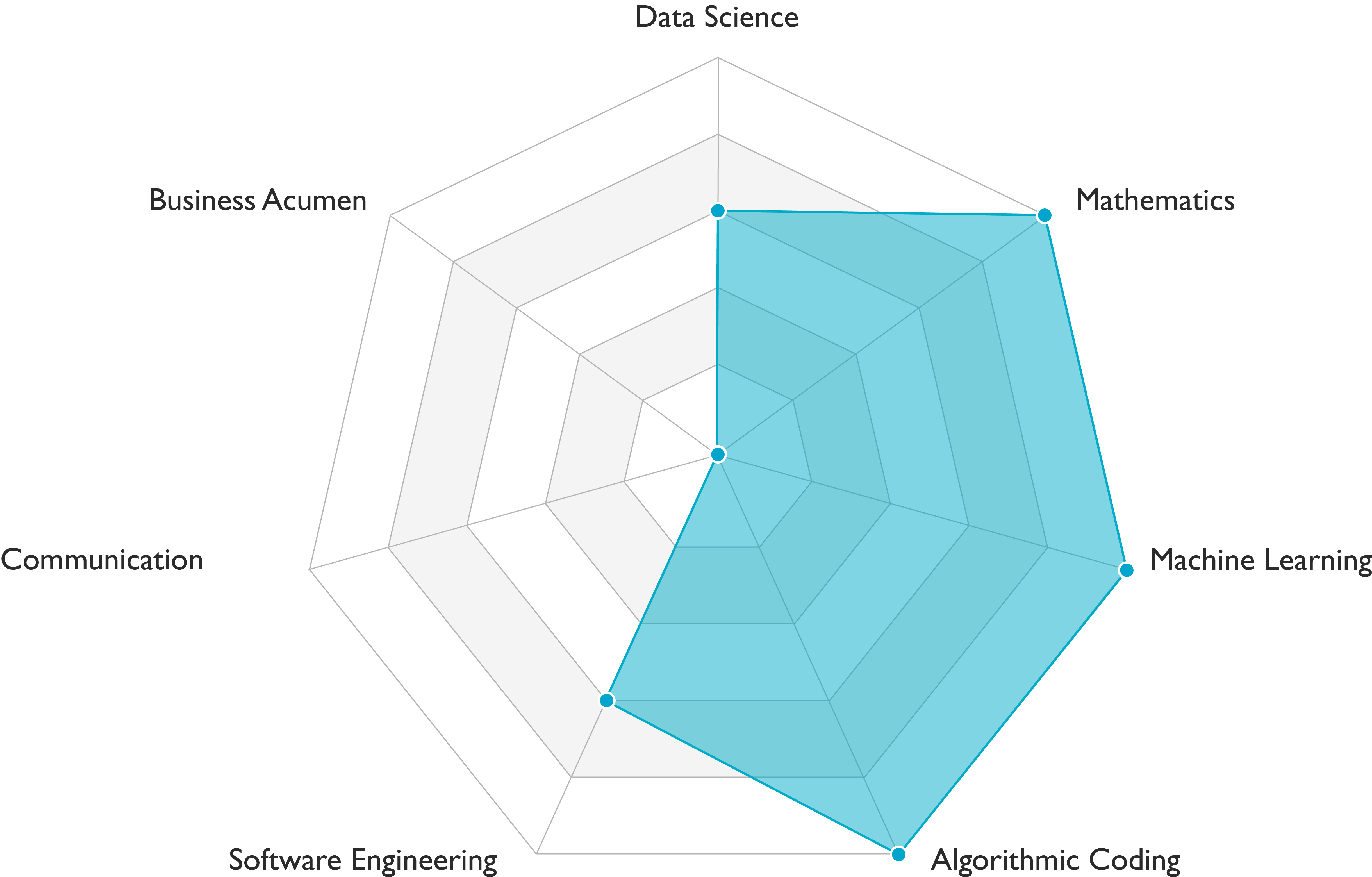 Machine learning engineers carry out data engineering, modeling, and deployment tasks. They demonstrate solid scientific and engineering skills (see Figure above). Communication skills requirements vary among teams.
Machine learning engineers carry out data engineering, modeling, and deployment tasks. They demonstrate solid scientific and engineering skills (see Figure above). Communication skills requirements vary among teams.
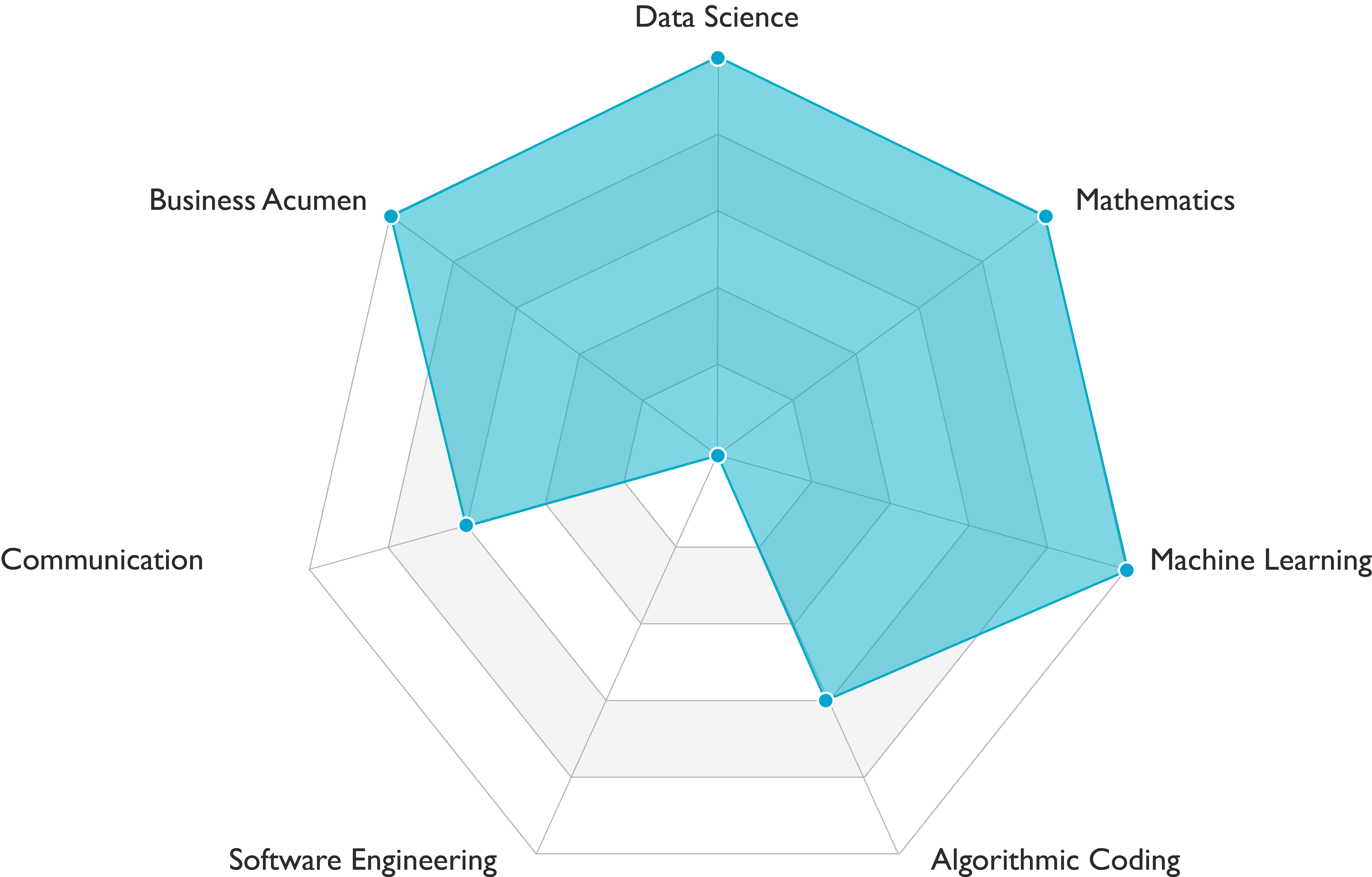 Data scientists carry out data engineering, modeling, and business analysis tasks. They demonstrate solid scientific foundations as well as business acumen (see Figure above). Communication skills are usually required, but the level depends on the team.
Data scientists carry out data engineering, modeling, and business analysis tasks. They demonstrate solid scientific foundations as well as business acumen (see Figure above). Communication skills are usually required, but the level depends on the team.
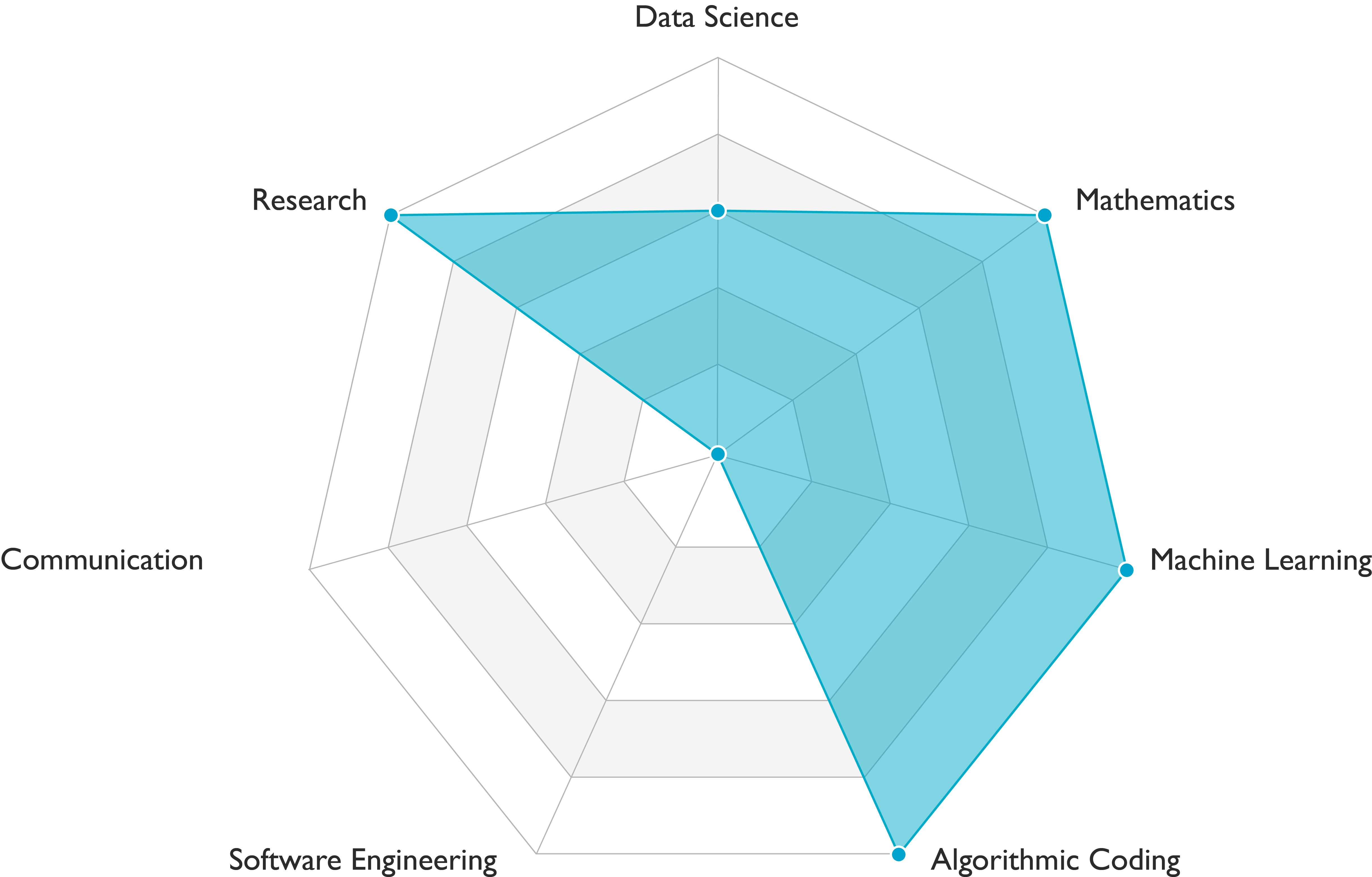 Machine learning researchers carry out data engineering and modeling tasks. They demonstrate outstanding scientific skills (see Figure above). Communication skills requirements vary among teams.
Machine learning researchers carry out data engineering and modeling tasks. They demonstrate outstanding scientific skills (see Figure above). Communication skills requirements vary among teams.
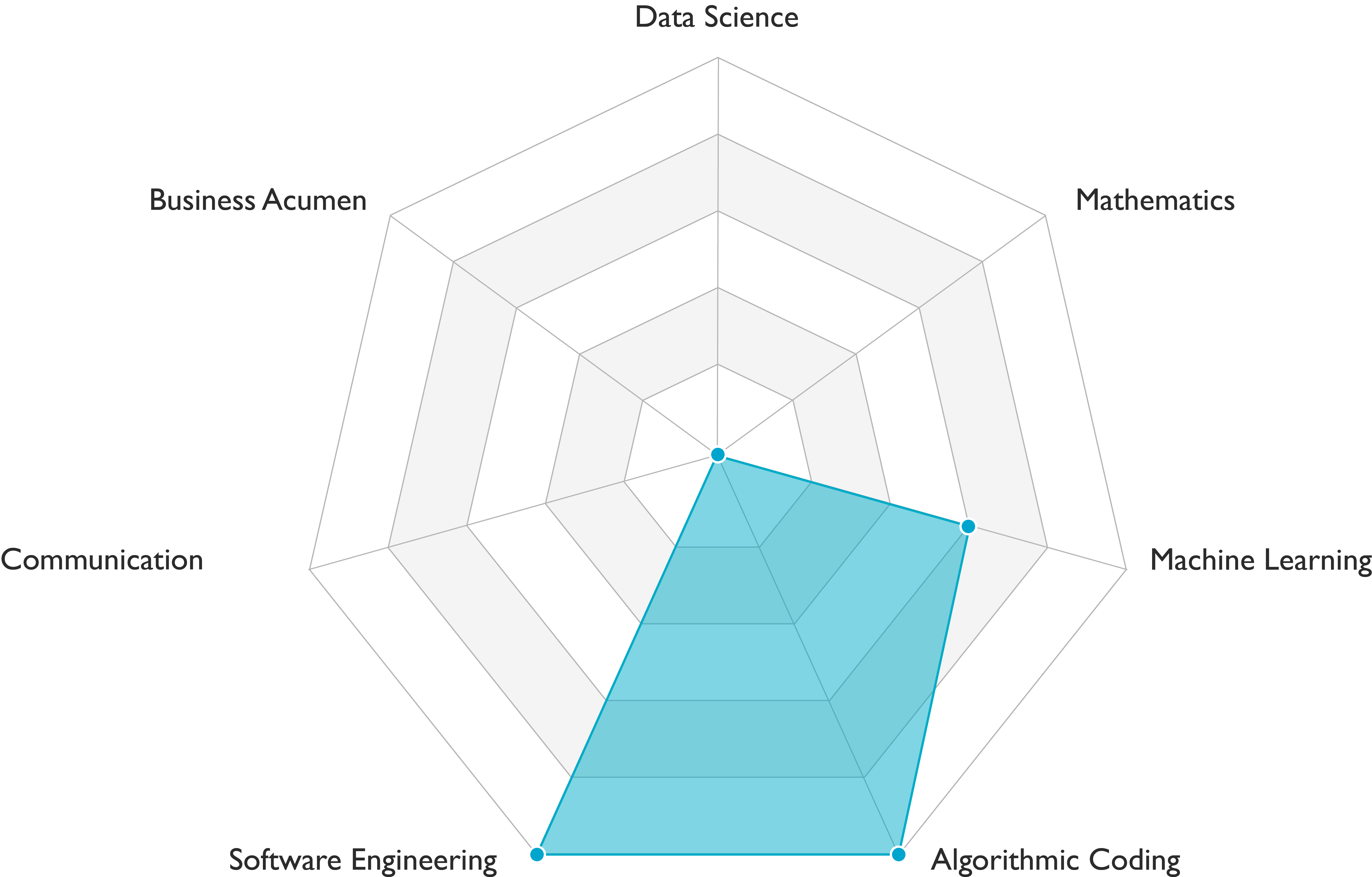 People who have the title software engineer-machine learning carry out data engineering, modeling, deployment and AI infrastructure tasks. They demonstrate solid engineering skills and are developing scientific skills (see Figure above). Communication skills requirements vary among teams.
People who have the title software engineer-machine learning carry out data engineering, modeling, deployment and AI infrastructure tasks. They demonstrate solid engineering skills and are developing scientific skills (see Figure above). Communication skills requirements vary among teams.


