
AI organizations divide their work into data engineering, modeling, deployment, business analysis, and AI infrastructure. Each task requires specific skills and can be the focus of multiple roles. Deep learning skills are sometimes required, especially in organizations focusing on computer vision, natural language processing, or speech recognition. If you apply to a role that carries out the modeling task such as Deep Learning Engineer (DLE), Deep Learning Researcher (DLR) or Software Engineer-Deep Learning (SE-DL), you’ll often encounter the deep learning algorithms interview during the onsite round. You can learn more about these roles in our AI Career Pathways report and about other types of interviews in The Skills Boost.
I What to expect in the deep learning algorithms interview
The interviewer will try to uncover how deeply you understand deep learning algorithms. Here’s a list of interview questions you might be asked:
- Explain how backpropagation works in a fully-connected neural network.
- Compute the number of parameters in a fully-connected, convolutional, or recurrent neural network.
- What is the difference between gradient descent, mini-batch gradient descent, and stochastic gradient descent?
- Explain how layers in the following list work: dense (i.e. fully-connected), convolutional, LSTM, pooling, etc. What are the hyperparameters of a given layer? What roles do they play?
- What methods are used to lower the variance? Explain the relevant methods, e.g. dropout, L1/L2 regularization, early stopping, etc.
- What are the benefits of batch normalization?
- How do residual networks differ from standard fully-connected neural networks?
II Interview tips
Every interview is an opportunity to show your skills and motivation for the role. Thus, it is important to prepare in advance. Here are useful rules of thumb to follow:
Listen to the hints given by your interviewer.
Example: You’re asked to calculate the number of parameters of a convolution layer and state that “the number of weights is $\text{filter width} \times \text{filter height} \times \text{number of filters}$.” If your interviewer questions you with “are you sure?” or “can you recall the shape of the input volume?”, there is a high chance your answer is imprecise or wrong. You should reconsider your answer. In this scenario, the interviewer expects you to remember that filters of a convolution layer have a depth equal to the depth of the input to the layer. Thus, the right count is $\text{filter width} \times \text{filter height} \times \text{input depth} \times \text{number of filters}$. If the interviewer asks you “is that all?,” it’s probably not. Parameters usually englobes weights and biases, so you’re expected to count the number of biases as well.
Study the data type that the company deals with.
Example: If the company stores petabytes of videos, learn about video data, video processing, and video compression methods ahead of time.
Study the type of algorithm relevant to the company’s product.
Interviewers tend to ask questions from their own area of expertise.
Example 1: If the team is working on a face verification product, review the face recognition lessons of the Coursera Deep Learning Specialization (Course 4), as well as the DeepFace (Taigman et al., 2014) and FaceNet (Schroff et al., 2015) papers prior to the onsite.
Example 2: If the team is building a robotic arm that will detect and grasp objects, you might want to look at popular object detection, object segmentation, and reinforcement learning algorithms. Furthermore, you can loose credibility by mispronouncing a technical word or acronym. In this scenario, pore over vocabulary such as piece-picking, sorting, kinematics, gears, grippers, and the like.
Write clearly, draw charts, and introduce a notation if necessary.
The interviewer will judge your scientific rigor.
Example: You’re asked to write the relationship between the input and the output of a softmax layer. Instead of writing $\text{softmax}(z) = \frac{e^z}{\sum e^z}$ , write $\text{softmax}(z_1, z_2, …, z_n) = (\frac{e^{z_1}}{\sum_{i=1}^n e^{z_i}}, \frac{e^{z_2}}{\sum_{i=1}^n e^{z_i}}, …, \frac{e^{z_n}}{\sum_{i=1}^n e^{z_i}})$. In this fashion, you’ll display your meticulous understanding of softmax applied to a multi-dimensional object and the shape of its output.
When you are not sure of your answer, be honest and say so.
Interviewers value honesty and penalize bluffing far more than lack of knowledge.
Example: Assume the interviewer asks you about the logistic loss. You remember logistic regression and the logistic function, but not the logistic loss. Rather than answering vaguely, you could say “I’m familiar with logistic regression and logistic function, but I don’t think I’ve heard of the term logistic loss. Could you provide more context?”. The interviewer might add that logistic loss is analogous to the binary cross entropy loss. It may help you answer, or at least invite the interviewer move to the next question.
Don’t mention methods you’re not able to explain.
Example: You’re explaining early stopping and state that “early stopping is a regularization method, like dropout.” In this scenario, you can expect the interviewer to ask: “could you explain dropout?”
When out of ideas or stuck, think out loud rather than staying silent.
Talking through your thought process will help the interviewer correct you and point you in the right direction.
III Resources
The deep learning section of the Workera test is a great way to prepare for this interview. It’ll provide you with a personalized study plan which includes a list of your strengths and weaknesses, along with curated training material to prepare for interviews or transition in your career. Additionally, here’s a list of useful resources to prepare for the deep learning algorithms interview.
- deeplearning.ai:
- Stanford Deep Learning class (CS230) by Andrew Ng and Kian Katanforoosh
- Deep Learning intuition (video)
- Attacking neural networks with adversarial examples and generative adversarial networks (video)
- Interpretability of a neural network (video)
- Deep reinforcement learning (video)
- Evaluation metrics (blog post)
- Hyperparameter tuning (blog post)
- Understanding gradient descent and backpropagation (blog post)
- Deep Learning by Ian Goodfellow, Yoshua Bengio and Aaron Courville (book)
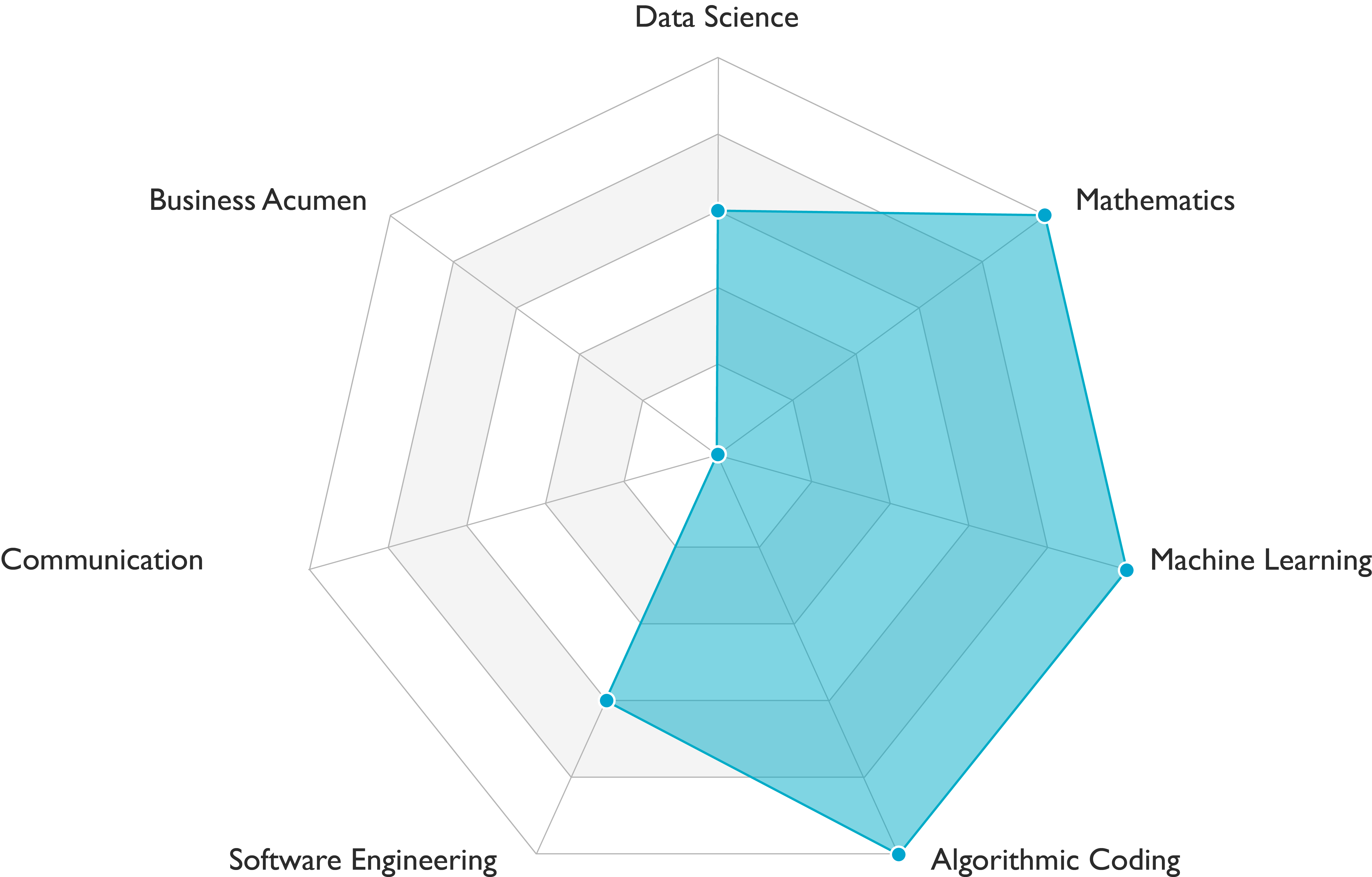 Deep learning engineers carry out data engineering, modeling, and deployment tasks. They demonstrate solid scientific and engineering skills. Communication skills requirements vary among teams. This role is a variant of machine learning engineer. It requires deep learning skills in addition to the skills profile presented in the figure above.
Deep learning engineers carry out data engineering, modeling, and deployment tasks. They demonstrate solid scientific and engineering skills. Communication skills requirements vary among teams. This role is a variant of machine learning engineer. It requires deep learning skills in addition to the skills profile presented in the figure above.
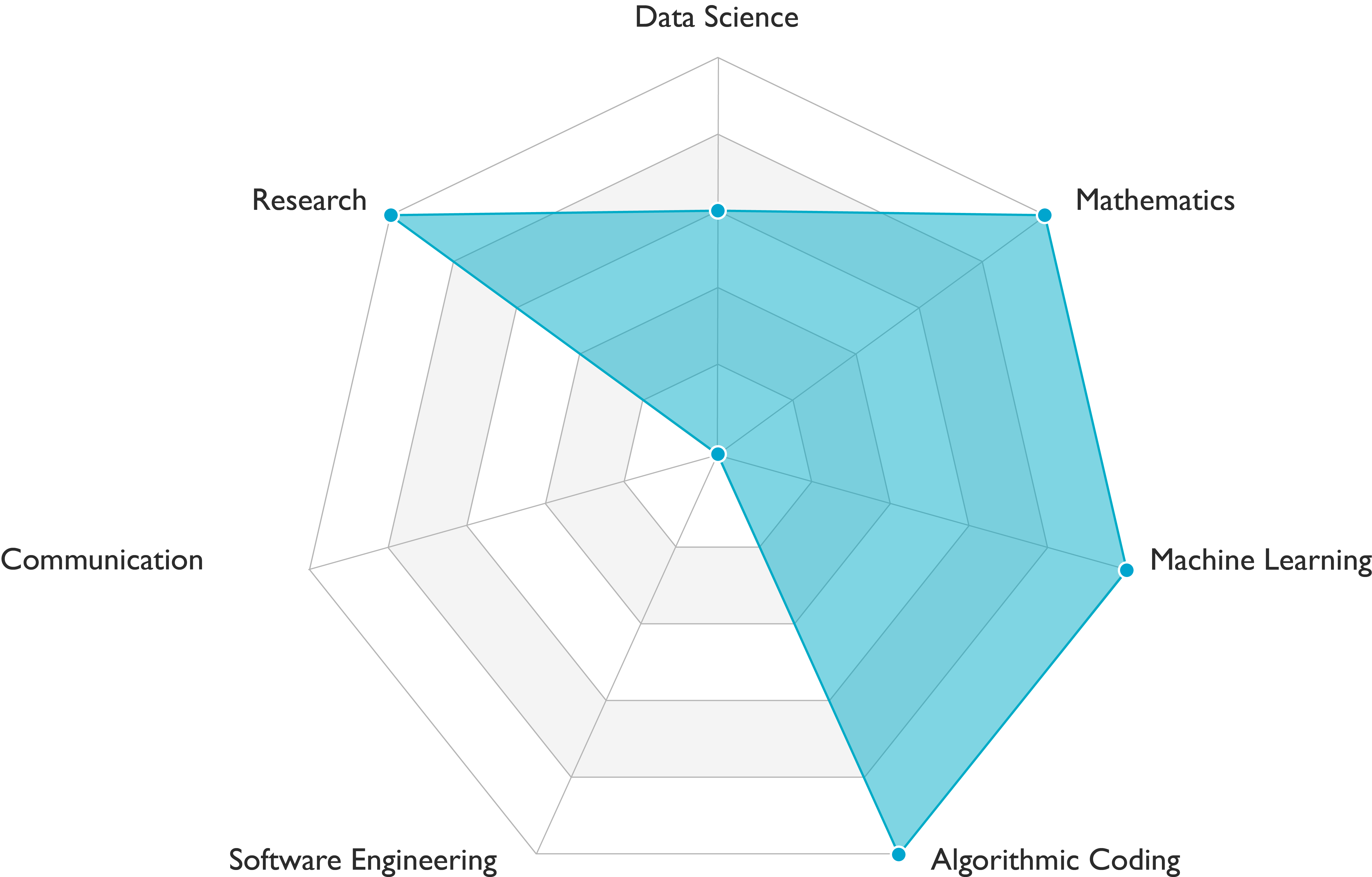 Deep learning researchers carry out data engineering and modeling tasks. They demonstrate outstanding scientific skills (see Figure above). Communication skills requirements vary among teams. This role is a variant of machine learning researcher. It requires deep learning skills in addition to the skills profile presented in the figure above.
Deep learning researchers carry out data engineering and modeling tasks. They demonstrate outstanding scientific skills (see Figure above). Communication skills requirements vary among teams. This role is a variant of machine learning researcher. It requires deep learning skills in addition to the skills profile presented in the figure above.
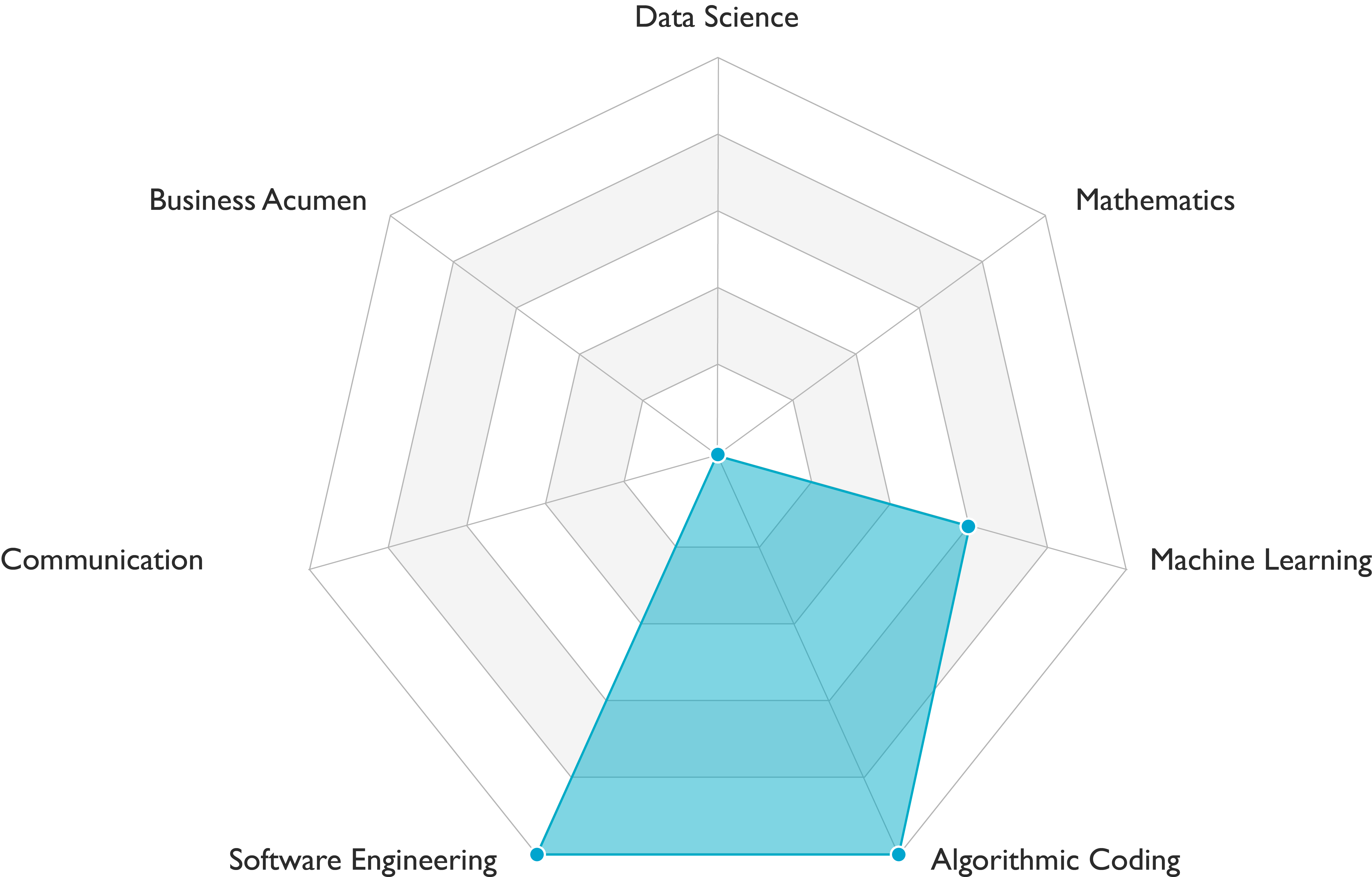 People who have the title software engineer-machine learning carry out data engineering, modeling, deployment and AI infrastructure tasks. They demonstrate solid engineering skills and are developing scientific skills. Communication skills requirements vary among teams. This role is a variant of software engineer-machine learning. It requires deep learning skills in addition to the skills profile presented in the figure above.
People who have the title software engineer-machine learning carry out data engineering, modeling, deployment and AI infrastructure tasks. They demonstrate solid engineering skills and are developing scientific skills. Communication skills requirements vary among teams. This role is a variant of software engineer-machine learning. It requires deep learning skills in addition to the skills profile presented in the figure above.
A video comprises a sequence of image frames displayed in rapid succession. Thus, understanding a video requires analysing each individual frame and the temporal correspondences lurking across multiple frames.
For instance, mispronouncing widely used dataset acronyms such as MNIST or CIFAR will affect your credibility.
The logistic loss measures the performance of a binary classifier.
Early stopping is a regularization method used to avoid overfitting when training a machine learning model with an iterative method like gradient descent.


